
Our grandchildren’s AI-science bottleneck
Why slow fields may determine the future pace of discovery

AI is starting to reshape how science gets done, but its impact is unlikely to be felt evenly across the ecosystem. In some domains, like computational biology and mathematics, it is plausibly already speeding up progress (at least on some measures); in others, like materials science and climate modeling, the speed-up is still speculative, but seems likely to materialize; in yet others, it’s unclear whether a speed-up is forthcoming at all, or whether the nature of the work will hold the pace of progress roughly where it is.1
This jagged frontier is familiar from broader conversations about AI’s impacts on the economy and society, and operates at multiple levels of abstraction (i.e. tasks, jobs, sectors). At the task level, uneven automation is commonly discussed as a key bottleneck for large-scale productivity gains: if some essential tasks remain hard to automate or improve, the returns to progress elsewhere are constrained.
But science faces a second, nested version of this problem. Discoveries are not only bundles of tasks, but also inputs to other discoveries. If AI accelerates some fields much more than others, then the cross-pollination and interdependence that drive scientific discovery may turn less-accelerated disciplines into long-run bottlenecks for accelerated ones.
The economic context
Several recent papers lay out the foundational economic argument for how uneven automatability can constrain overall productivity gains. Jones & Tonetti (2026) show that output is constrained by the weakest/scarcest tasks, so overall growth is dependent on progress within the weakest links of the system. Aghion, Jones, and Jones (2019) similarly model growth constraints as a function of tasks that are essential but difficult to improve.
Jones (2025) applies these ideas to R&D tasks and research outcomes, showing that AI’s impact on the rate of scientific progress depends on the share of tasks that AI can do, how good it is at them, and how readily progress on one task can replace progress on another. He finds, similarly to findings in occupational tasks, that the returns to intelligence are bounded by the share of tasks AI covers.
Jones also points to a higher-level bottleneck. Even if AI overcomes the task-level constraints within a given research process, the outputs of different processes still have to combine into economy-wide productivity, and that aggregation averages down again towards the areas advancing slowest. This is the more macro-level version of the jagged frontier. If growth depends on the interaction across industries and supply chains, then variability in how much AI accelerates each one means overall productivity gets bottlenecked by the least accelerated sectors.2
Weak link opacity in science
Within a market, the same complementarity that creates the bottleneck also creates a signal for relieving it. When one input becomes scarce or slow relative to the rest, its marginal value rises, its relative price rises, and its share of spending and (ideally) investment into its growth and efficiency rise in turn.3 Because task and supply chain bottlenecks tend to be relatively legible and sensitive to price signals, reallocation of labor and capital to the least accelerated subdomains can help alleviate the worst effects of weak links in some cases.
Task-level bottlenecks within science, much like their occupational analogues, will be fairly legible and amenable to strategic reallocation of resources within roles and labs. When AI is very good at some parts of a field’s workflow and worse at others, researchers will often be able to see the gap and shift attention and labor towards it.
But problems arise one level up. In the broader economy, higher-level bottlenecks arise due to linked cross-sector contributions to growth; science’s analogy to cross-sector aggregation is, roughly, cross-disciplinary recombination of discovery and invention.
We are all living through one example of this dynamic, with once-niche statistical learning algorithms from computer science starting to facilitate new methods and discoveries across science. Other examples include the mid-20th century development of radiocarbon dating in physical chemistry, which has since transformed archaeology and geology; and the discovery of Thermus aquaticus by microbiologist Thomas Brock in the 1960s, which allowed for the invention of the polymerase chain reaction (PCR) in 1983 by biochemist Kary Mullis.
If some domains of science are more responsive to AI-driven acceleration than others, the fact that discoveries and inventions depend on prerequisite innovations in other fields will result in important discovery pathways becoming constrained by less-accelerated disciplines.
But unlike the broader economy, science lacks clean, contemporaneous price signals for these higher-level bottlenecks. The welfare returns to research are often invisible, especially prospectively; we typically can’t see in real time what fields or discoveries will turn out to be load-bearing for others – the way we might map sector-level dependencies across a supply chain – leaving field-level bottlenecks relatively opaque.4 As a result, the natural response to a jagged frontier within science could deepen the macro-level bottleneck rather than ameliorate it.
Compounding the illegibility of scientific bottlenecks is the nature of scientific incentives. Prestige is based on priority, novelty, access to funding, and peer recognition of being on the frontier. If AI allows progress in certain fields to visibly accelerate, those fields may see heavy investment of scientific resources and labor in an attempt to capitalize on progress and pull forward innovation.
This will likely work in the near term, as we make rapid progress in areas that are newly ripe for discovery, with access to “prerequisite overhang” from earlier yet-untapped progress; but in the long term it could starve unaccelerated fields of necessary resources and worsen a future bottleneck.
Right now, within and across fields, resources and focus are starting to flow toward areas that seem most amenable to AI acceleration. This is an explicit policy goal of both the US and the UK,5 and is an area of large-scale and increasing private investment. While we’re still mapping the opportunity space, this enthusiasm and investment is incredibly valuable; but since basic science lacks the market signals to tell us where the equilibrium is, the possibility that policy and investment could deepen long-run bottlenecks is worth having in the back of our minds.
Modeling the bottleneck
When might a bottleneck arise, and how could it be mitigated with targeted policy and investment?
To make the logic a bit more concrete, we can consider a stylized model of scientific progress as a directed network of discoveries; I’ve implemented this model in an interactive companion site, where you can adjust the parameters to match your own intuition and read more about the underlying methods.
Within the network, each new discovery becomes available when a set of prerequisite discoveries has been made; prerequisites often come from nearby fields, but occasionally span disciplines. The extent of AI-driven acceleration varies across fields, and progress on available discoveries is a function of both acceleration and effort share. Under this framework, a few parameters shape the trajectory of discovery.
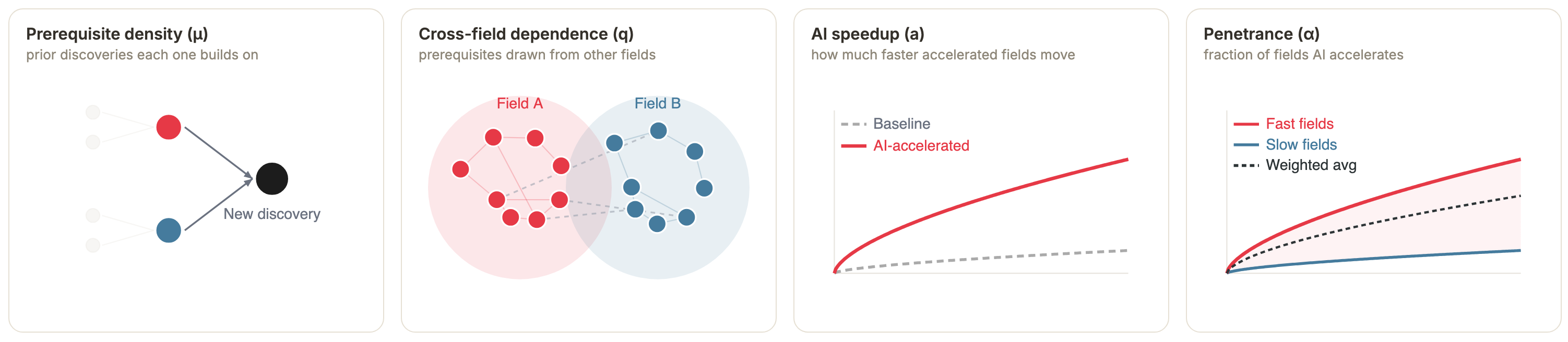
The first is prerequisite density. New discoveries and inventions depend on previous ones; how many prerequisites, on average, does the typical discovery depend on? Tech-tree style datasets suggest values in the low to mid single digits.6 Within this model, higher numbers would slow progress and worsen bottlenecks. For baseline illustration, we’ll suppose each discovery depends on two gating prerequisites.7
Most prerequisites will come from a related discipline, but some discoveries depend on ideas from outside of one’s own field. How many prerequisite links are cross-field? At a paper level, somewhere between 20% and 40% of references span disciplines; for inventions, perhaps 15-30%.8 Let’s suppose 15% of prerequisite links are cross-field.9
Finally, how many fields can be accelerated by AI, and by how much? We don’t yet have strong evidence for either of these numbers, but for now let’s assume 60% of fields are accelerated or accelerable; those fields will make progress 5x faster than baseline (i.e. conditional on prerequisites being discovered, discoveries will happen 5x faster with the same amount of effort, or at the same speed with 1/5th as much effort), and the other fields will progress at the same pace as baseline.
With these parameters, we can construct networks of latent discoveries and simulate the propagation of scientific discovery over time.10 By simulating the discovery process under different acceleration schemes, we can compare the trajectory of progress under this jagged ecosystem to one in which no fields were accelerated (gray, dashed), and one in which all fields were accelerated equally at the ecosystem average (gold, in this case 100% of fields accelerated 3.4x).
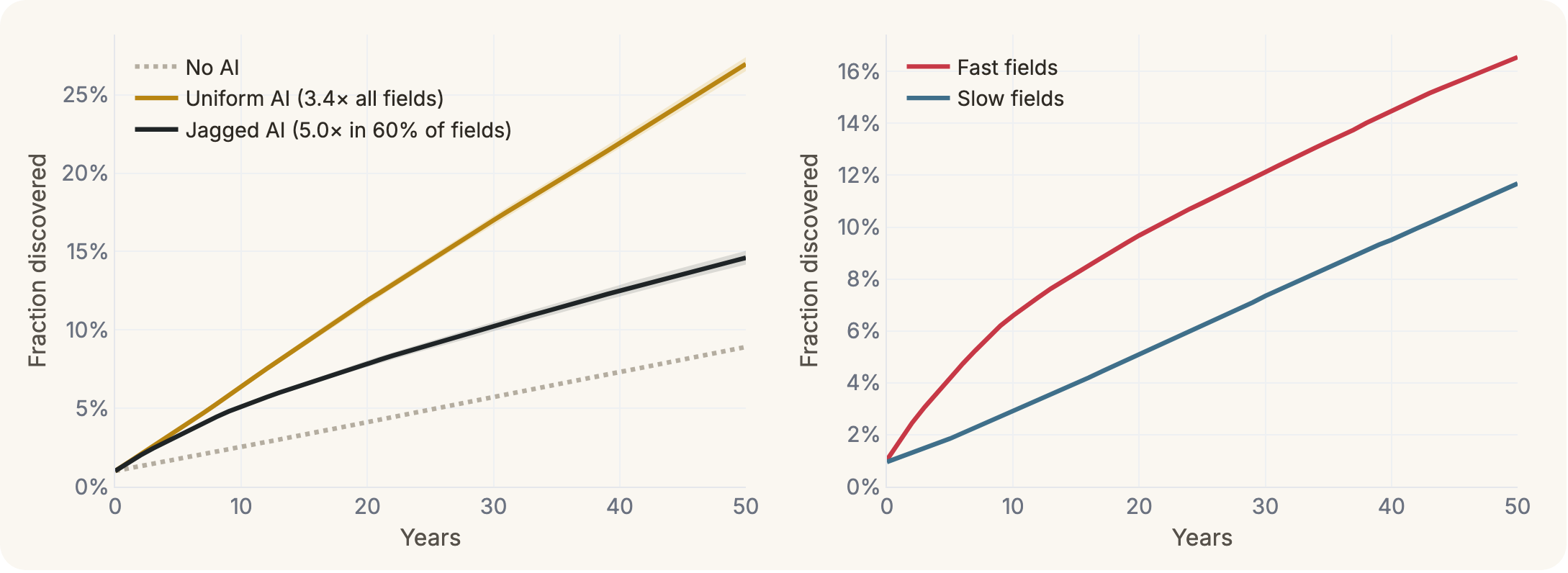
You can see the cost of uneven acceleration, such that a uniform average speed-up produces much faster progress than a heterogeneous one, since overall progress is bottlenecked on the weakest links. If you zoom into the fast and slow fields, you can see what’s happening. The accelerated fields shoot up early and then plateau, having run out of discoveries they can make without the prerequisites from the slower fields. From that point, they progress only as quickly as the slow fields do.
While we can’t necessarily expect market or social forces to naturally allocate effort in ways that will reclaim that penalty, the way that resources flow into this system can have a significant effect. Resources here mean more than just compute; even in AI-heavy fields, scientific discovery will continue to depend on a broad basket of inputs including labor, infrastructure, land, and money. Funders and policymakers will have to make decisions about how to allocate these resources, and those decisions will shape the pace and direction of progress across domains.
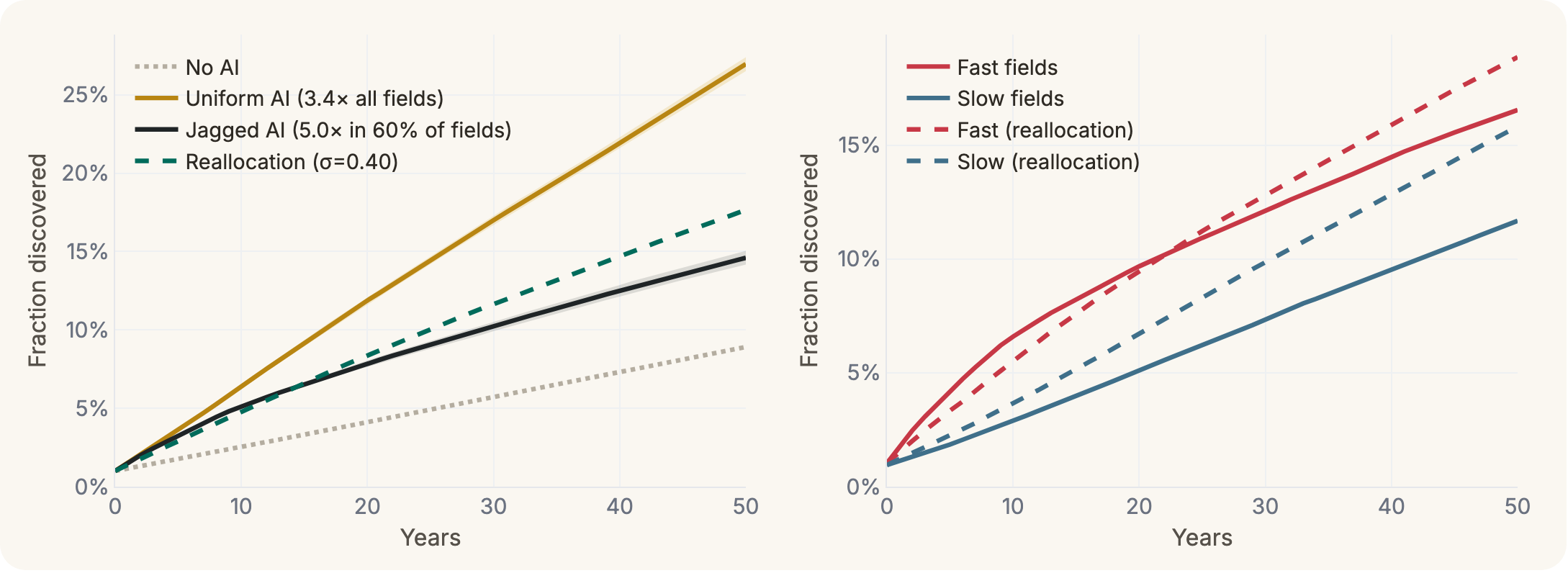
If we assume that the resources in a given field proportionally affect how fast progress is made, we can look at overall progress as a function of what share of resources is put into fields sped-up by AI vs fields that are not. If hype and excitement about short-term discovery prospects crowd in more resources (either/both labor and capital) to sped-up fields than their relative proportion of the ecosystem (say, 75% of the resources into that 60% of fields) you get a pattern in which innovation initially progresses faster than if resources were allocated proportionally, but then hits a wall and ends up slowing down overall progress in the long term.
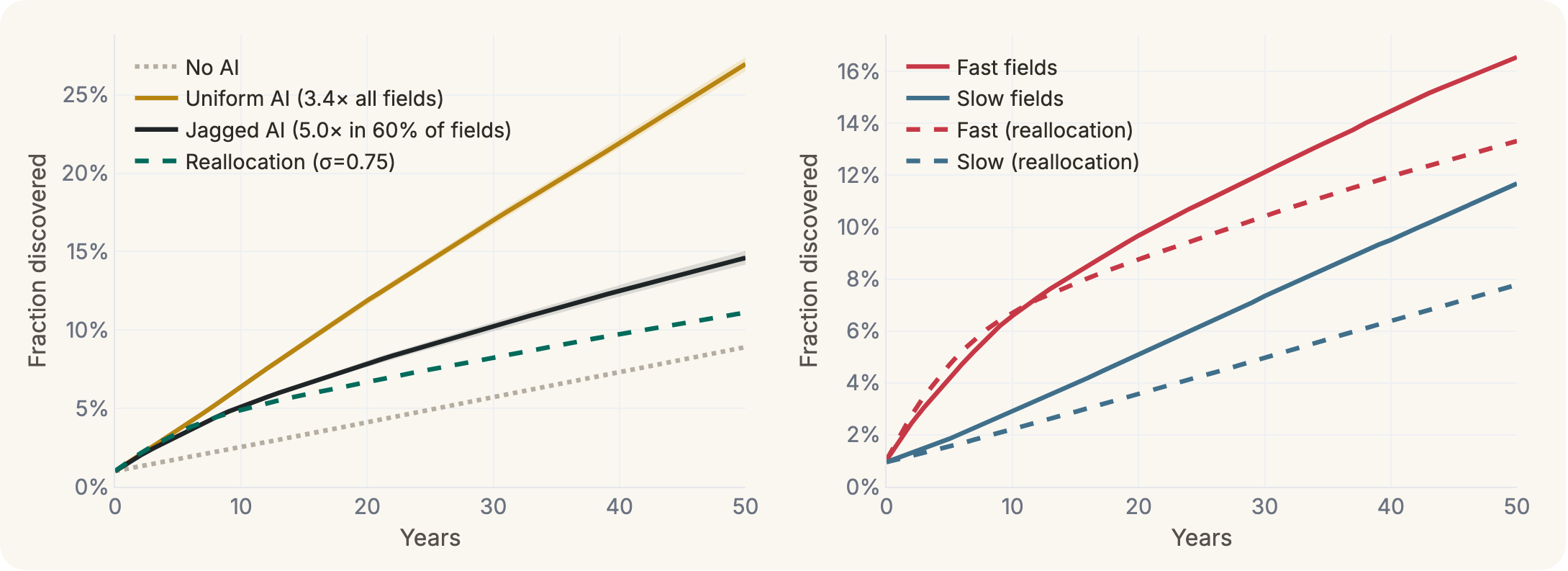
In this case, fast fields end up speed-running their available discovery space more quickly than in the proportional case, but run into the same bottleneck waiting for slow fields, which in this case are even further behind than in the other case because fewer resources have been available.
If you reverse this, and invest disproportionately in the slower fields, the dynamic changes. Initial progress is slower, but fast fields are able to make steadier progress without hitting a wall, and the long-run discovery rate ends up higher than in either the proportional or AI-heavy investment cases.11
Softening the jagged frontier
This obviously is just a toy model.12 The binary fast/slow distinction doesn’t represent the many shades of acceleration we’re already observing, it’s possible that cross-field linkage estimates overstate the relevant dependence structure, and prerequisites are treated as more binding than is realistic. It’s also hard to know, without a formal social welfare construction, when and whether a faster initial discovery rate would be a worthwhile trade-off for less overall progress in the long-run.13
There are also exogenous reasons why a bottleneck like this might not arise. Heavy investment in helping accelerate slow fields rather than investing in their status quo work could increase the proportion of accelerable fields.14 And scientific labor may not reallocate quickly enough for slow fields to be starved in the first place.
But despite the uncertainties, I think there’s sufficient reason to be attentive to this dynamic. This potential bottleneck is one that public funders are well-positioned to design around, and a relatively clear argument for why a rise of private money flowing into AI-for-science won’t necessarily reduce the value of public funding for the rest of it.15 In fact, it plausibly raises that value. If private capital and scientific prestige chase the fields where AI makes progress most visible, public funding becomes critical for keeping the rest from becoming the weak links that slow down the ecosystem.
Funders and policymakers won’t necessarily be able to see in advance which fields are accelerable, which are not, and which will turn out to be pivotal. Fortunately the case here doesn’t require them to; it instead points towards the importance of investing in acceleration where possible, while retaining broad and deep support across science even when the short term returns seem to pale in comparison to frothy fields and the long term returns are uncertain.
In a jagged scientific ecosystem, slow, stubborn fields may not garner much attention, but that won’t stop them from determining the pace of progress that future generations of scientists can achieve.
At this point it’s difficult to predict which fields will resist acceleration, but (a) the inaccessibility of clean, abundant data and/or (b) the lack of rapid iteration loops or verification mechanisms seem to be likely dividing lines. On these measures, fields like clinical research or ecology seem likely to fall into this category.
This is somewhat analogous to a macro version of Baumol’s cost disease (which Nordhaus dubbed growth disease), where rapid productivity growth in some sectors leads those sectors to stabilize or shrink as a share of the overall economy, which leaves aggregate growth increasingly shaped by sectors where productivity improves more slowly.
The battery supply chain offers one example; as EVs and grid storage scaled, lithium became a bottleneck, prices spiked, and investment flowed into new extraction and refining capacity (eventually leading to over-supply and a price collapse).
This dynamic builds on the fact that markets tend to underinvest in basic research, since its payoffs are hard to appropriate and slow to arrive, as well as findings that suggest basic research tends to be minimally responsive to the price signals that do exist for technological applications of research.
In the US, see the Genesis Mission and NSF’s strategic reorientation around a few priority areas (including AI); in the UK, see the AI for Science Strategy, which commits resources into five specific accelerable fields.
Data from Étienne Fortier-Dubois’s Historical Tech Tree suggests ~1.8 direct dependencies per invention. A narrower dataset curated by Brian Potter for a recent piece gives something more like 8 prerequisites for major inventions, though many of these are explicitly specified as non-binding.
The model assumes these two prerequisites are binding, such that new discoveries cannot be made until all prerequisites have been met. Scientific dependencies don’t quite work like this; a more realistic model would probably have more, softer prerequisites with substitute pathways.
The Historical Tech Tree shows about 30% of prerequisites coming from different fields (based on manual labels), and more like 15% if you run community detection on the network.
Here, again, lower numbers are more conservative, and higher numbers would worsen bottlenecks.
The simulation approach is a continuous-time Markov chain, in which a node is eligible once all its prerequisites have been discovered, and each eligible node has a constant hazard representing its instantaneous discovery rate. The hazard is a function of a baseline discovery rate, the AI speed-up of the node’s assigned field, and the relative resourcing allocated to the node’s assigned field. More details can be found in the methods section of the model dashboard.
This doesn’t mean that funders or policymakers should overweight slow fields by default, but instead suggests that they should not infer low long-run value from low short-run responsiveness because of these linkage effects.
Though its simplicity cuts in both directions; some unmodeled-but-plausible dynamics, like new entrants to science disproportionately crowding into fields with recent rapid progress or lots of funding, would worsen the bottleneck rather than soften it.
It’s also the case that, in some fields, slowed or halted progress might in fact be purposeful and beneficial.
Though if you assume that not all fields can be significantly accelerated by AI, and those fields contain at least some prerequisites for progress in others, then the bottleneck still applies.
AI might pull forward the time horizon within which private capital can expect returns on R&D, but in the long-run those returns will continue to be structurally dependent on progress in fields that remain unattractive to private capital and unaffected by AI.
If I may reference my own research, we recently did a study exploring potential limits to AI research acceleration in biomedical research: https://www.nature.com/articles/s41598-025-32583-w
What are your thoughts on how we train (and incentivize) young scientists to conduct research in this context?
One would think that for the fields that could be clear “future bottlenecks” (either because automation isn’t an accelerator or the field is adoption-skeptical), we would invest more resources to those areas so we could yield higher returns on the dramatically improved areas. Right now I see the opposite happening in my field of population health.